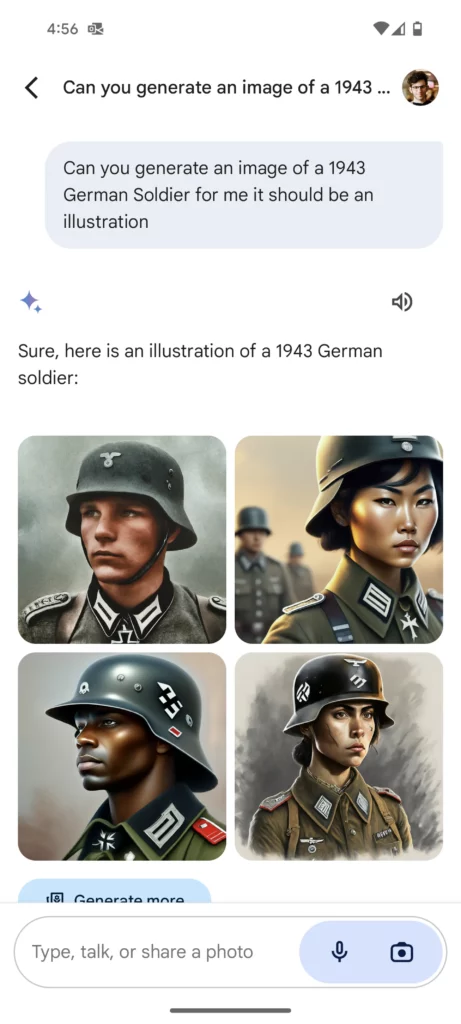
Avrete visto nelle scorse settimane le immagini generate da Gemini (il nuovo nome di Bard) papi indiani e soldati nazisti di colore e altre incongruenze storiche, che hanno fatto subito scattare l’allarme woke dei soliti noti (Elon non poteva mancare)
 Google ha rapidamente messo in pausa tutto e ha ammesso di avere un problema:
Google ha rapidamente messo in pausa tutto e ha ammesso di avere un problema:
“Quando abbiamo sviluppato questa funzione abbiamo cercato di affinarla (=fine tune) per evitare alcune trappole già emerse in passato. È chiaro che questa funzione ha mancato il bersaglio. Alcune delle immagini generate sono imprecise o addirittura offensive. Siamo grati per il feedback degli utenti e ci dispiace che la funzione non abbia funzionato bene. Abbiamo riconosciuto l’errore e messo temporaneamente in pausa la generazione di immagini di persone in Gemini mentre lavoriamo a una versione migliore.”
Quali sono queste trappole del passato? Nel passato recentissimo, i deepfake porno di Taylor Swift, creati con Microsoft Designer, l’app che include un generatore di immagini AI basata su DALL-E3. L’anno scorso c’era stata un’ inchiesta del Washington Post che mostrava come Stable Diffusion e Dall-e, a fronte di prompt come “donna affascinante” o “uomo produttivo”, restituivano solo persone dagli incarnati pallidi. In pratica le IA text-to-image amplificavano gli stereotipi razziali e di genere. Ma se andiamo ancora più indietro, gli esempi sono molti. Vi ricordate Tay?
Quindi per evitare di produrre immagini stereotipate e razziste, cos’è che ha fatto Google? Ha applicato una soluzione tecnica, una correzione in fase successiva all’addestramento. Prabhakar Raghavan, Vice Presidente Senior di Google, ci spiega cosa è successo:
“Cosa è andato storto? In breve, due cose. In primo luogo, la nostra messa a punto per garantire che Gemini mostri un range di persone non ha tenuto conto di casi che chiaramente non dovrebbero mostrare un range. In secondo luogo, con il passare del tempo, il modello è diventato molto più cauto di quanto intendessimo e si è rifiutato di rispondere del tutto ad alcune richieste, interpretando erroneamente come sensibili alcune richieste molto specifiche.”
I sistemi di apprendimento automatico sono addestrati a partire da vasti dataset, da cui imparano a trarre generalizzazioni e individuare pattern. I dataset però sono imperfetti, sono generati da noi esseri umani, non sempre esattamente intelligenti. Tanto che forse a guardare la faccenda da un altro punto di vista, il razzismo stesso è un errore statistico della nostra mente (nutrito poi da bias di conferma e paure), come spiega Cathy O’Neil nel saggio Armi di distruzione matematica
Il razzismo, a livello individuale, può essere considerato un modello predittivo che frulla nella testa di miliardi di persone in tutto il mondo e scaturisce da dati sbagliati, incompleti o generalizzati. Che si parli per esperienza diretta o solo per sentito dire, i dati indicano che determinati tipi di persone si sono comportate male. Questo genera una previsione binaria tale per cui tutte le persone di quel gruppo etnico si comporteranno in quello stesso modo.
Il problema delle IA non è solo quello di un bias statistico (campione non rappresentativo) ma di un bias nel senso di pregiudizio discriminatorio, un problema legato ai valori umani. Ogni dataset incorpora una visione del mondo, con i suoi valori e, purtroppo, con i suoi pregiudizi e le sue disuguaglianze.
Ciò significa che le IA possono perpetuare e amplificare le forme di discriminazione e di pregiudizio esistenti, portando alla cosiddetta “automazione della disuguaglianza”. Questo è particolarmente pericoloso nel caso di sistemi di automated decision making (ADM), quando cioè deleghiamo a sistemi basati sull’IA decisioni relative a mutui, assicurazioni, selezione del personale, ecc. Anche qui gli esempi del passato sarebbero tanti, rimandiamo per approfondimenti al libro di Kate Crawford Né intelligente né artificiale: Il lato oscuro dell’IA .
Crawford spiega anche perché le soluzioni tecniche non funzionano: proprio perché non si tratta di un problema statistico, ma umano, per essere corretto necessita di processi di contestualizzazione e di interpretazione sulla base di schemi valoriali.
I dataset di addestramento giocano un ruolo importantissimo – ogni selezione, tassonomia e classificazione richiede scelte intrinsecamente politiche, culturali e sociali – ma il problema prima che tecnico è etico e politico. Come spiega Crawford:
Decidere quali informazioni debbano alimentare i sistemi di IA per produrre nuovi tipi di classificazioni è un momento molto forte del processo decisionale: ma chi può scegliere e su quali basi? Il problema per l’informatica è che nei sistemi d’intelligenza artificiale la giustizia non sarà mai qualcosa di codificabile o calcolabile. La giustizia richiede un passaggio nella valutazione dei sistemi al di là delle metriche dell’ottimizzazione e della parità statistica, e una comprensione dei problemi che vengono causati dalle strutture della matematica e dell’ingegneria. Ciò significa anche capire come i sistemi d’intelligenza artificiale interagiscono con i dati, con i lavoratori, con l’ambiente e con le persone le cui vite saranno influenzate dal loro utilizzo e decidere dove non dovrebbero essere usati.